
はじめに
会社で他社車のBMデータ整理することになった。canってなに?の状況からデータ処理まで何とか頑張ったのでまとめる。記事を書き上げるのを優先したため、分かりにくい部分はご勘弁。
pythonでの読み取り方法
ここではanacondaのパッケージをインストールしていることを前提とする。
こちらを参考にしたが、ところどころ自分で試行錯誤しているところがあるので、参考になればと思う。
コンソール上で必要なパッケージをインストール
コンソール上で下記のコマンドを実行
pip install cantools
pip install python-can
筆者はspyderを使っているため、以下の赤〇のところで上記のコマンドをうち、エンターした。
blfの読み取り (import&準備)
先ほど必要なパッケージをインストールしたのでさっそくここで使う。canの読み取りで使うのは、
import cantools
import can
それぞれの役割は理解していない。。
そしてcsv化で使うpandas
import pandas as pd
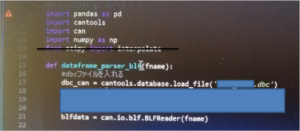
外部関数として読み取り部分を作成している。
引数はblfのファイル名(~.blf)としている。
.dbcファイルにはbitrateや変数名が格納されているようで、
「dbc_can」に情報を格納する。
続いてblfデータを「blfdata」に格納する。
抽出部分
canのデータはmessageとして各信号に応じたsampringで吐き出されているようだ。そこでmessageを抽出し、変数として保存する必要がある。
信号が吐き出される時刻が信号ごとにそれぞれ異なるため、
下記変数を持たせておく。
timestamp_shoki=0
また、あらかじめ変数を格納する箱を作成しておく。
outputー=[]
まずは欲しい信号のmessageを受け取る部分
さきほど作成したblfには沢山のメッセージが詰まっているため、
欲しいメッセージを抽出する。
抽出方法は、
for msg in blfdata
とし、messageごとに識別する。
識別は、messageのidを見る
msg.arbitation_id==int(ー)
このidは??と迷うだろう。dbcを色々見るとどうにか分かるだろう
下図の〇はid、△はmessage番号、□は各信号の名前。
書き間違えるとエラー出るのでトライ&エラーでどうにかなるだろう。
識別した後はそのmsgに含まれる情報を格納する。
temp=dbc_can.getーー
の部分だ。式が長いためーーで省略している。
次にtempに格納した変数を取り出す。
ー=temp["xx"]
xxにはdbcに記載の文字を入れる。文字を間違えるとエラーになるので注意。
おそらくtemp["xx"]でtempからxxの箱に入っている値を取り出す処理をしているのであろう。
最後に箱に変数をappendする。
注:はじめのmessageはtimestamp_shokiの時間を格納するために使っている。

読み取り部分

DBC中身
csv化
上記までではpythonの通常のlistが作成されている。これをnumpyやpandasで扱えるようにすればあえてcsvにする必要もないが、一応手順を載せる。まずはpandasで扱えるように先ほど作ったlistを下記のように変換する。
df=pd.DataFrame[ー]
ーは先ほど作成したlist名
次にコラムの作成
df.columns=(["a","b","c","d"])
a~dには先ほどお好きに。。
最後にpandasでcsv作成。
df.to_csv(ー)
ーにはファイル名を入れる。
使い方
上記で外部関数として作っており、メインのところでこれを実行する。
引数はファイル名としているので、メインのところで同じフォルダ中のblfファイル名を抽出して、実行するのが都合がよいだろう。
list=glob.glob(‘*.csv’)
print(list)
for x in list:
abcd(x)
abcdは先ほどの外部関数。メイン関数で使えるようにimportしておくこと。
ちなみにglobも使えるようにimportを忘れずに。
最低限のコード
こちらは動作確認未だが、作ってみた。
import pandas as pd
import cantools
import can
filename=input("please input dbc filename:")
print(filename)
dbc_can=cantools.database.load_file(filename)
file=input("please input blf filename:")
print(file)
blfdata=can.io.blf.BLFReader(file)
BO=input("please input BO Num.:") #red circle at picture
print(BO)
name=input("please input Message Num.:") #red triangle at picture
print(name)
variable=input("please input variable.:") #red squere at picture
print(variable)
#initialized time constant
timestamp_ini=0
#initialized list
outputlist=[]
for msg in blfdata:
if(msg.arbitration_id==int(BO)):
temp=dbc_can.get_message_by_name(name).\
decode(msg.data, decode_choices=False)
aaa=temp[variable]
#bbb=temp[]
#ccc=temp[]
if(timestamp_ini==0):
timestamp_ini=msg.timestamp
else:
Timer=msg.timestamp-timestamp_ini
outputlist.append([Timer,aaa])
df=pd.DataFrame(outputlist)
df.columns=(["Time","aaa"])
df.to_csv(file[:-4]+".csv") #.blf -> .csv注意点
この手順でやってみてもよくわからないエラーが出ることがある。エラーメッセージ見て対応すればどうにかなるだろう。一点だけよくありそうなエラーを載せる。これはメッセージ中にデータの重複があると言っているようだ。そこでdbc中のテキストを編集する。重複している片方の行を削除すれば解決する。例えば、上で載せた「DBC中身」にある赤□の行が重複行に該当しているならば削除する。

余談
会社ではcanalyzerやcanoeのライセンスが限られているはずだ。自分もdemo版でトライしようとしたが、messageが1000行?超えると読み取れないようだ。もしかしたら自分の知識不足で出来るかもしれないが、データ処理もpythonに任せるのでどうにか読み取りからデータ処理まで一括で出来るように頑張ったのがこの記事だ。。このために色々ネットで調べたが情報少なく、英語の記事も多かったため、いつかアクセス数稼ぎのために英語化したい。。。

