
はじめに
これまでスキャンの話ばかりであったが、とうとう手書き削除アプリ開発に取り組む。結論からいうと失敗。実施したことと構築できた機能、失敗要因についてまとめていきたい。
当初の目論見
こちらの論文を参考に以下の機能を作成していった。
が、いずれもそこそこの完成度なもののトータルで使い物になるものができなかった。悔しい。。
| No | 項目 | 自信度 |
|---|---|---|
| 1 | 二値化で背景白に | 100点 |
| 2 | 細線化 | 100点 |
| 3 | 交点検出&交点削除 | 100点 |
| 4 | エッジ削除 | 100点 |
| 5 | 輪郭検出 | 90点 |
| 6 | 局所分散の閾値調整 | 60点 |
それぞれについて
詳細を順次述べたい。
二値化で背景白に
これは特に問題はなかった。
img=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #グレースケールにして
_, gray = cv2.threshold(
img, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU) #二値化
image = cv2.bitwise_not(gray) #白黒反転して
#grayといいつつ文字は黒(値0)、そこにimgの値を足せば、白(値255)は頭うち
#他は普通に足される。opencvの場合
image_shiro_kuro=cv2.add(gray,img)こちらが変換前
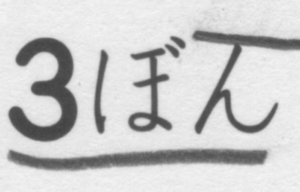
変換後だ

細線化と交点検出&交点削除
細線化はopencvの関数があるようだがscikit imageを使った。ちょっとつまづいたので備忘もかねて。関数のimportは忘れずに。ここに書いていないが。。
#まずは二値化
_, gray = cv2.threshold(
img_gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
#で、細くしたいのを白くする。これ大切
image = cv2.bitwise_not(gray)
#で、255の要素を1に置き換え。これも大事
image[image == 255] = 1
# 細線化 スケルトン化
# https://code.tiblab.net/python/opencv/img_skeletonize
# ↓の2行でopencvでも扱えるようになる。np.uint8に型変換しないとダメ
ske = skeletonize(image)
image = (ske * 255).astype(np.uint8)
# あとはカラーで扱うように
img = cv2.cvtColor(image, cv2.COLOR_GRAY2RGB)そして細線後の交点検出と交点削除。一発で処理できる関数が以外に見当たらず、ちょっと工夫。結構いい感じにできた。考え方はkernelを当てて、合致しないところは収縮処理させること。
# kernelの準備。np.uinit8にすべし
kernel_koten=np.array([[[0,1,0],[0,1,1],[0,1,0]],
[[0,1,0],[1,1,1],[0,0,0]],
[[0,1,0],[1,1,0],[0,0,0]],
[[0,1,1],[1,0,0],[0,1,0]],
[[0,0,0],[1,1,1],[0,1,0]],
[[1,0,1],[0,1,0],[1,0,0]],
[[1,0,0],[0,1,1],[0,1,0]],
[[1,0,0],[0,1,0],[1,0,1]],
[[1,0,1],[0,1,0],[0,0,1]],
[[0,0,1],[0,1,0],[1,0,1]],
[[1,0,0],[0,1,1],[1,0,0]],
[[1,0,1],[0,1,0],[0,1,0]],
[[0,0,1],[1,1,0],[0,0,1]],
[[0,1,0],[0,1,0],[1,0,1]],
[[0,1,0],[1,1,0],[0,0,1]],
[[0,1,0],[0,1,1],[1,0,0]],
[[1,0,0],[0,1,1],[0,1,0]],
[[0,0,1],[1,1,0],[0,1,0]]],
dtype=np.uint8)
# kernelを何回もあてる
for i in range(18):
image_koten = cv2.erode(image,kernel_koten[i,:,:],
iterations = 1) #収縮
# 収縮されず生き残ったものをどんどん足していく。~~totはimageをALL0にしたもの
image_koten_tot=cv2.add(image_koten_tot,image_koten)
# ここで膨張させて。
k_para=9 ##調整パラ##
kernel = np.ones((k_para,k_para),np.uint8)
image_koten_tot = cv2.dilate(image_koten_tot,kernel,iterations = 1) #imgの中で、image_koten_totが白のところと同じセルを赤くしている
img[image_koten_tot>0.01*image_koten_tot.max()]=[0,0,255]
# これを加工して交点にかぶせれば輪郭を分割できるはずこちらが処理したイメージ いかがだろうか
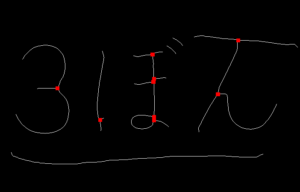
エッジ削除
これは簡単だ。収縮するのみ。一応コードを載せておく。解説なし
image = cv2.erode(image,kernel1,iterations = 1)
輪郭検出と局所分散調整
全体の輪郭検出は特に問題はないだろう。個別の輪郭に対する処理を一工夫したので載せる。
for i, contour in enumerate(contours):
## 他のドリルで枠内に記述があったのでひと手間
Area_con=cv2.contourArea(contour) #面積
Len_con = cv2.arcLength(contour,True) #周長
hie_co=hierarchy[0][i][2]
hie_oya=hierarchy[0][i][3]
if Area_con<1: ##小さい面積除外
continue
if Area_con>50000000: ##大きい面積除外
continue
##hierarchy [Next, Previous, First_Child, Parent]##
##contourの決定 ここで枠内か否か判定。考え方は周長と面積の比##
if Area_con/Len_con<100: ##調整パラ 空間あり除外
con_temp=[contour]
elif hie_co==-1:
con_temp=[contour,contours[hie_oya]]
else:
continue
img_mask=img.copy()
img_mask[:,:]=0
##cv3->4でcontoursの形状が変わるため注意??##
cv2.drawContours(
img_mask, con_temp, -1, 255, thickness=-1)
# ここで特定の輪郭のみ元画像から抽出
img_AND=cv2.bitwise_and(img_tegaki,img_mask)
# 白や黒に近いノイズを削除
img_AND=np.where(img_AND>254,0,img_AND)
img_AND=np.where(img_AND<1,0,img_AND)
# 0の要素を圧縮。計算速度アップするか?
img_AND=img_AND[img_AND.nonzero()]
# ここで標準偏差
bunsan_std=np.std(img_AND)
# 閾値以上なら残す。考え方は鉛筆だとまばらに紙にのるか?
if bunsan_std>16: ##調整パラ
img_tegaki_shukei=cv2.add(img_tegaki_shukei,img_mask)
# 上がうまくいけばマスク画像が完成し、消せるのだが。。。一応鉛筆書きのところを抜き出せた

ところが標準偏差の閾値(赤点線)がギリギリ 使い物にならないだろう
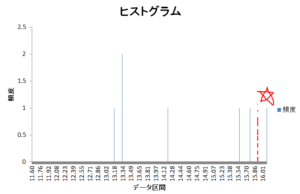
ちなみにこちらがわく内をうまく抜き出せた例
元
後 若干枠が残っているように見えるが前処理の収縮で枠が切れている

おまけ
ちなみに前画像にて赤色の丸が上手く消えているのにお気づきであろうか。これもちょっと一工夫しているのだ。HSVに変換している画像に対し、彩度があるものは0にする処理だ。これで赤に限らず色は消えてくれる。はじめはこちらのような情報が多い画像をやっつけようとして実は挫折しているのだ。これができず、より簡単なものをしても、今回のような結果なのである。。
hsv_1=img_hsv.copy()
hsv_1[:, :, 1] = np.where(
img_hsv[:, :, 1]>10, 0, img_hsv[:, :, 1]) ##調整パラ##
img=cv2.cvtColor(hsv_1, cv2.COLOR_HSV2BGR)まとめ
今回は失敗してしまったものの機能構築の観点では色々出来上がったのではないだろうか。特に使い道はないが。。
敗因を考えると、
・元々の画像の印刷品質が悪かった
・手書きを識別する考え(局所分散)が良くない?
とかある。deep learningをやってみるか。。自分にできるのか。。
