
会社でデータ処理をするときには大抵csvか、タブで区切られたテキストファイルなどが対象になるであろう。これをエクセルに変換し、ある列にlowpassをかけ、FFTしてグラフにしてとやっている人が多数であろう。自分もその中の一人だった。今は徐々に自動化に取り組んでいる。
ここで格言を一つ
「なあ、光一。会社はお前を育ててくれはしないぞ」(左利きのエレン より)
はじめに
この記事では以下の4つを紹介する。
- csvの読み込み
- lowpass filter (ローパスフィルター)
- FFT
- グラフ作成
本編
csvの読み込み
以下にコードを示す。ポイントは、
- csv_readerの使い方のさわりだけ紹介
- 数字の行だけを対象にするため、読み込み行を指定
- 日本語フォントを読み込ませるとエラー出るため
- やろうとすればファイル名により処理が変えられる
- pandasの行列操作が面倒なことに気づいた。「.iloc」をつけるのが。。
- 配列操作はnumpyにお任せがよいかも
- 処理したい列は変数で持たせる
- 「delimiter=","」のところでカンマ以外の区切りも対応できる。半角スペースとか。。
import csv
import glob
import numpy as np
### 同じフォルダ中のcsvの読み込み ###
list=glob.glob('*.csv')
print(list)
for x in list:
### ファイル名によって処理を変えたい場合こちらで分岐 ###
'''
if 'no1.csv' in x:
print('no1') ### ファイル名にno1がついたときの処理
elif '_no2.csv' in x:
print('no2') ### ファイル名にno2がついたときの処理
elif '*_no3.csv' in x:
print('no3') ### ファイル名にno3がついたときの処理
else:
print("error")
'''
data_tot=[] #配列を用意
i=0 #with openの前に持ってくる
### CSVの読み込み 自分は行ごとに読み込むのが好み。 ###
### 大体のデータロガーは前半に色々な情報書いているため ###
with open(x,mode="r",encoding="utf-8") as fp:
csv_reader=csv.reader(fp,delimiter=",") #,区切りでないファイルのときdelimiter
for row in csv_reader:
if i>=1: #2行目以降を追加。日本語読み込むとエラーになるため
data_tot.append(row) #headerは無視
i=i+1
#print(i)
data_tot = np.array(data_tot, np.float32) #要素を型変換。csv_readerは文字列
#print(data_tot) #確認
shori_r=3 #処理したい列!!!!
data=data_tot[:,shori_r]ローパスフィルター
以下にコードを示す。ポイントは、
- データ数を2の累乗以外にも対応。普通2の累乗じゃないとNAになってしまう。。
- 方法は、足りないデータは一番最後のデータで補間というシンプルな方法
- 自分は信号処理の専門ではないので良しあしはおいておく
- こちらを別ファイルとしてメイン関数と同じフォルダに格納し適宜使う
- 戻り値はxと同じ要素数のfilter処理後のデータ
こちらを参考にした。
https://watlab-blog.com/2019/04/30/scipy-lowpass/
import numpy as np
from scipy import signal
import math
#バターワースフィルタ(ローパス)
def lowpass(x, samplerate, fp, fs, gpass, gstop):
### 注意 fp<fs じゃないと使えないかも ###
### データ補間 2の累乗に合わせる ###
yososu=len(x)
print(yososu) #確認
njo=math.ceil((math.log2(yososu))) #2の何乗?
hoju=2**njo-1-yososu
if hoju != 0:
dainyu=np.full(hoju,x[-1])
x=np.append(x,dainyu)
### データ補間 ここまで ###
fn = samplerate / 2 #ナイキスト周波数
wp = fp / fn #ナイキスト周波数で通過域端周波数を正規化
ws = fs / fn #ナイキスト周波数で阻止域端周波数を正規化
N, Wn = signal.buttord(wp, ws, gpass, gstop) #オーダーとバターワースの正規化周波数を計算
b, a = signal.butter(N, Wn, "low") #フィルタ伝達関数の分子と分母を計算
y = signal.filtfilt(b, a, x) #信号に対してフィルタをかける
y = y[:yososu] #はじめに受け取った要素数を返す
return y FFT
以下にコードを示す。ポイントは、
- データ数を2の累乗以外にも対応。普通2の累乗じゃないとNAになってしまう。。
- 方法は、足りないデータは一番最後のデータで補間というシンプルな方法
- 自分は信号処理の専門ではないので良しあしはおいておく
- こちらを別ファイルとしてメイン関数と同じフォルダに格納し適宜使う
- 戻り値は「周波数」、「周波数ごとの振幅」
- 対象が完全に周期的なものでないのが多いので窓関数は使わない
import numpy as np
import math
def FFT(x, dt):
### データ補間 2の累乗に合わせる ###
yososu=len(x)
print(yososu) #確認
njo=math.ceil((math.log2(yososu))) #2の何乗?
hoju=2**njo-1-yososu
if hoju != 0:
dainyu=np.full(hoju,x[-1])
x=np.append(x,dainyu)
### データ補間 ここまで ###
### FFT ###
## 窓関数
window_n = np.hanning(len(x))
# x=x*window_n #周期的な信号のときに使ったほうがよい?
#print(window_n)
## 処理
F = np.fft.fft(x) # 変換結果
freq = np.fft.fftfreq(len(x), d=dt) # 周波数
Amp = np.abs(F/(len(x)/2)) # 振幅
freq=freq[1:int(len(x)/2)]
Amp=Amp[1:int(len(x)/2)]
return freq, Amp グラフ作成
以下にコードを示す。ポイントは、
- 一枚のファイルに複数のグラフを載せる。A3横用紙をイメージ
- 他は特にないかな。。
### グラフにしてpngで保存 ###
### 保存する紙の広さ ###
fig=plt.figure(figsize=(18,12)) # 縦横比 (1:1.4) がきれいかも サイズは(横,縦)
ax1=fig.add_subplot(2,3,1) #縦,横,何番目
ax1.grid()
ax1.plot(data_tot[:,0],data_tot[:,1],\
color="red",linestyle="-",\
label="non-noize") ### ここで横軸の長さをそろえておくと報告書に載せやすい
ax1.legend() #凡例表示
ax1.set_xlim([0,5]) #軸調整 subplot!!
ax1.set_ylim([-2,2]) #軸調整 subplot!!
ax2=fig.add_subplot(2,3,2)
ax3=ax2.twinx() #2軸使ってみる
ax2.grid()
ax2.plot(data_tot[:,0],data_tot[:,3],\
color="red",linestyle="-",\
label="shori_taisho")
ax3.plot(data_tot[:,0],data_filt[:],\
color="blue",linestyle="-",\
label="shori")
ax2.legend(loc="upper left") #凡例 左上に
ax3.legend(loc="upper rigtht") #凡例 右上に
ax2.set_xlim([0,5]) #軸調整 subplot!!
ax2.set_ylim([-2,2]) #軸調整 subplot!!
ax3.set_ylim([-2,2]) #軸調整 subplot!!
ax4=fig.add_subplot(2,3,4) #縦,横,何番目
ax4.grid()
ax4.plot(fft,amp,\
color="red",linestyle="-",\
label="fft") ### ここで横軸の長さをそろえておくと報告書に載せやすい
ax4.legend() #凡例表示
### 一番右は余白にしてみる ###
fig.savefig(x[:-3]+"png")
### グラフを閉じる。これをしないとメモリーが消費される ###
plt.close()
plt.clf()全体通して
こちらがメイン関数全体。
ここに書いていることが理解できれば、急に沢山のデータ渡されてグラフにしといてちょと言われても、対応できるようになる。。はず。
import lowpass #ユーザー関数
import FFT #ユーザー関数
import glob
import numpy as np
import csv
import matplotlib.pyplot as plt
### 同じフォルダ中のcsvの読み込み ###
list=glob.glob('*.csv')
print(list)
for x in list:
### ファイル名によって処理を変えたい場合こちらで分岐 ###
'''
if 'no1.csv' in x:
print('no1') ### ファイル名にno1がついたときの処理
elif '_no2.csv' in x:
print('no2') ### ファイル名にno2がついたときの処理
elif '*_no3.csv' in x:
print('no3') ### ファイル名にno3がついたときの処理
else:
print("error")
'''
data_tot=[] #配列を用意
i=0
### CSVの読み込み 自分は行ごとに読み込むのが好み。 ###
### 大体のデータロガーは前半に色々な情報書いているため ###
with open(x,mode="r",encoding="utf-8") as fp:
csv_reader=csv.reader(fp,delimiter=",") #,区切りでないファイルのときdelimiter
for row in csv_reader:
if i>=1: #2行目以降を追加。日本語読み込むとエラーになるため
data_tot.append(row) #headerは無視
i=i+1
#print(i)
data_tot = np.array(data_tot, np.float32) #要素を型変換。csv_readerは文字列
#print(data_tot) #確認
### 大体のデータの1列目は時間 ###
dt=data_tot[1,0]-data_tot[0,0]
samplerate=1/dt
shori_r=3 #処理したい列
data=data_tot[:,shori_r]
### lowpass ###
#print(data) #確認
fp = 3 #通過域端周波数[Hz]
fs = 5 #阻止域端周波数[Hz] fp<fs
gpass = 3 #通過域端最大損失[dB]
gstop = 40 #阻止域端最小損失[dB]
data_filt = lowpass.lowpass(data, samplerate, fp, fs, gpass, gstop)
### FFT ###
fft, amp=FFT.FFT(data, dt)
### グラフにしてpngで保存 ###
### 保存する紙の広さ ###
fig=plt.figure(figsize=(18,12)) # 縦横比 (1:1.4) がきれいかも サイズは(横,縦)
ax1=fig.add_subplot(2,3,1) #縦,横,何番目
ax1.grid()
ax1.plot(data_tot[:,0],data_tot[:,1],\
color="red",linestyle="-",\
label="non-noize") ### ここで横軸の長さをそろえておくと報告書に載せやすい
ax1.legend() #凡例表示
ax1.set_xlim([0,5]) #軸調整 subplot!!
ax1.set_ylim([-2,2]) #軸調整 subplot!!
ax2=fig.add_subplot(2,3,2)
ax3=ax2.twinx() #2軸使ってみる
ax2.grid()
ax2.plot(data_tot[:,0],data_tot[:,3],\
color="red",linestyle="-",\
label="shori_taisho")
ax3.plot(data_tot[:,0],data_filt[:],\
color="blue",linestyle="-",\
label="shori")
ax2.legend(loc="upper left") #凡例 左上に
ax3.legend(loc="upper rigtht") #凡例 右上に
ax2.set_xlim([0,5]) #軸調整 subplot!!
ax2.set_ylim([-2,2]) #軸調整 subplot!!
ax3.set_ylim([-2,2]) #軸調整 subplot!!
ax4=fig.add_subplot(2,3,4) #縦,横,何番目
ax4.grid()
ax4.plot(fft,amp,\
color="red",linestyle="-",\
label="fft") ### ここで横軸の長さをそろえておくと報告書に載せやすい
ax4.legend() #凡例表示
### 一番右は余白にしてみる ###
fig.savefig(x[:-3]+"png")
### グラフを閉じる。これをしないとメモリーが消費される ###
plt.close()
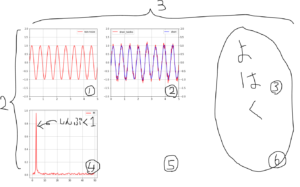
plt.clf()グラフの完成イメージ
pngファイルで出てきます。色々メモを上書きしていますが、手書きチックじゃないところが出力です。
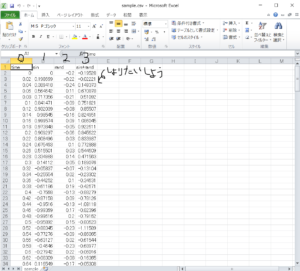
入力csvイメージ
こんな感じのデータセットを今回用意しました。一番左は0番目となります。今回は処理対象の番号は3なので、
「shori_r=3」としている!
おわりに
自分はこれまでデータ処理にpandasを勧めてきたが、好みが変わってきた。これからnumpyでやろうと思う。
参考書
ちょっと奮発してこれを買って読んでみたい。。
がもう若くない。子育てでお金絞られる。。ため若い技術者に託す。
自分が若いときは新品の参考書を自己投資という名のもと心おきなく買えたものだ。今は乞食のごとく、ネット情報をかき集めている。。
リンク
リンク

