
はじめに
表形式のデータを社内のDBに格納するとき、特にx軸、y軸、z軸を持つデータで可変のものは扱いに悩むだろう。とりあえず、エクセルにしてファイルサーバーに置くだと、味気ない。。エクセルに入れるデータをルール化すればちょっとは利活用できる形になるはず。
やったこと
エクセルに入れるデータをルール化し、表もデータとして扱えるようにしてみた。エクセルは↓のような形。
エクセルの例

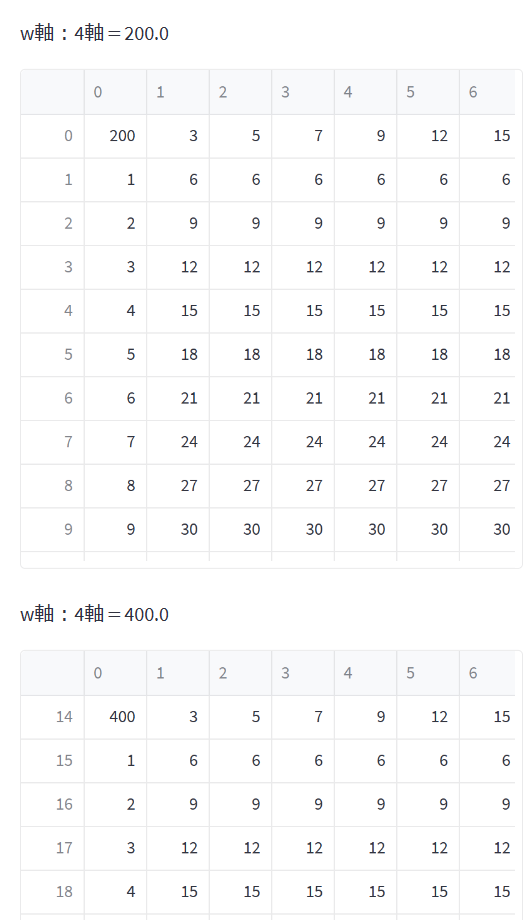
アプリでの表示
例のごとくstreamlitを使って、pandasのData frameとしてとりだすと↓のようになる。本気出せばもうちょっとカッコよい表にできるが、まずはこの程度。ag-gridとか使うといい。
streamlit(抜粋)
プログラム
こちらのとおり。これで2D~4DのデータもDB→エクセル→streamlitを経由して活用できるだろう。DB自体はAPIでアクセスすればよいだけ。
import streamlit as st
import pandas as pd
from st_aggrid import AgGrid,ColumnsAutoSizeMode
import json
##########設定###########################
st.set_page_config(
page_title="agg cheat",
layout="wide", )
def Njigen(fname):
tmp=pd.read_excel(fname)
numjigen=tmp.iloc[0].notnull().sum()
return numjigen,tmp.iloc[:1,:]
#########################################
st.markdown("test")
test=pd.read_excel("test2D.xlsx", header=None, skiprows=5)
tmp=Njigen("test2D.xlsx")
if tmp[0]==2:
test=test.iloc[:,:2]
test.columns=tmp[1].iloc[0,:2]
test
testT=test.T
testT[0:1]
testT[1:2]
test=pd.read_excel("test3D.xlsx", header=None, skiprows=5)
tmp=Njigen("test3D.xlsx")
tmp[0]
if tmp[0]==3:
st.markdown(f'x軸:{tmp[1].iloc[0,0]}')
st.markdown(f'y軸:{tmp[1].iloc[0,1]}')
st.markdown(f'z軸:{tmp[1].iloc[0,2]}')
test
test=pd.read_excel("test4D.xlsx", header=None, skiprows=5)
tmp=Njigen("test4D.xlsx")
if tmp[0]==4:
st.markdown(f'x軸:{tmp[1].iloc[0,0]}')
st.markdown(f'y軸:{tmp[1].iloc[0,1]}')
st.markdown(f'z軸:{tmp[1].iloc[0,2]}')
st.markdown(f'w軸:{tmp[1].iloc[0,3]}')
Inull=test.loc[test[0].isna()].index.to_list()
df=[]
for i, x in enumerate(Inull):
if i==0:
x
df.append(test[:x])
tmp1=x
else:
df.append(test[tmp1+1:x])
tmp1=x
df.append(test[tmp1+1:])
for i in df:
st.markdown(f'w軸:{tmp[1].iloc[0,3]}={i.iloc[0,0]}')
i
おわり
マップ情報の管理は難しいからとりあえずエクセルファイル自体をやりとりしようという人はあまり信用できない。streamlit上から直接編集できるようにすれば、エクセルを介在しているが、ユーザにとっては脱エクセルが実現できる。

コメント